This document describes the implementation and internal architecture of the WIQA Engine and outlines the multi-step process that is required to check a set of RDF graphs against a WIQA policy and to generate WIQA explanations.
The WIQA engine is a library for filtering Semantic Web information. The input is a set of RDF graphs, each named with a URI. The output is an RDF graph that contains only those triples from the source graphs that match a certain policy.
In addition to the filtering, the engine can generate textual explanation objects that explain to a user why a certain triple was accepted into the output graph. The power of the policy language can be extended by defining custom Functions and Extensions.
Policies are defined using the WIQA-PL policy language. Its syntax is inspired by the SPARQL query language. The WIQA engine builds on ARQ, the SPARQL implementation that is shipped with the Jena Semantic Web Framework.
This document assumes familiarity with the WIQA engine's public API.
| Package | Purpose |
|---|---|
| de.fuberlin.wiwiss.wiqa | The engine's public API. |
| de.fuberlin.wiwiss.wiqa.bindings | Code for dealing with streams of solutions and for grouping solutions by shared variable values. Solutions are called bindings inside the codebase because the ARQ class com.hp.hpl.jena.query.core.Binding is used as an implementation of the concept. |
| de.fuberlin.wiwiss.wiqa.count | Code for evaluating count constraints. Implements the algorithm described in section 7. |
| de.fuberlin.wiwiss.wiqa.engine | The query engine's core, especially those parts that hook into Jena's ARQ query processor. |
| de.fuberlin.wiwiss.wiqa.example | Some usage examples. |
| de.fuberlin.wiwiss.wiqa.explanation | Code for generating explanations. Implements the algorithm described in section 8. |
| de.fuberlin.wiwiss.wiqa.gp | Code for arranging graph patterns into a tree. Implements the algorithm described in section 6. |
| de.fuberlin.wiwiss.wiqa.extensions | Contains various functions and extensions that add capabilities to the engine, such as a complex trust filtering metric. |
| de.fuberlin.wiwiss.wiqa.parser | Hand-authored support code for the JavaCC-generated WIQA-PL parser. |
| de.fuberlin.wiwiss.wiqa.parser.javacc | JavaCC-generated parser for WIQA policies. |
| de.fuberlin.wiwiss.wiqa.vocab | RDF vocabularies used by WIQA. |
A WIQA policy is a set of patterns and constraints. Policies operate on an input dataset (described in the API overview). Input triples that match the patterns and constraints are accepted into an output RDF graph. Policies are written using the WIQA-PL language, whose features are described in the WIQA-PL Language Specification.
The following example policy has five graph patterns, several explanation templates, and a count constraint. Namespace prefix declarations have been omitted.
NAME "Asserted by analysts with at least 3 positive ratings"
DESCRIPTION "Only accept information that has been asserted
by analysts who have received at least 3 positive ratings."
PATTERNS {
GRAPH fd:GraphFromAggregator {
EXPL "it was asserted by " ?authority " and " .
?GRAPH swp:assertedBy ?warrant .
?warrant swp:authority ?authority .
}
GRAPH ?graph2 {
?authority rdf:type fin:Analyst .
}
GRAPH fd:GraphFromAggregator {
EXPL ?authority2 " claims that " ?authority " is an analyst." .
?graph2 swp:assertedBy ?warrant2 .
?warrant2 swp:authority ?authority2 .
}
GRAPH ANY {
EXPL ?authority "has received positive ratings from" .
?rater fin:positiveRating ?authority .
FILTER (wiqa:count(?rater) >= 3) .
}
GRAPH fd:BackgroundInformation {
EXPL ?rater "who works for" ?company .
?rater fin:affiliation ?company .
}
}
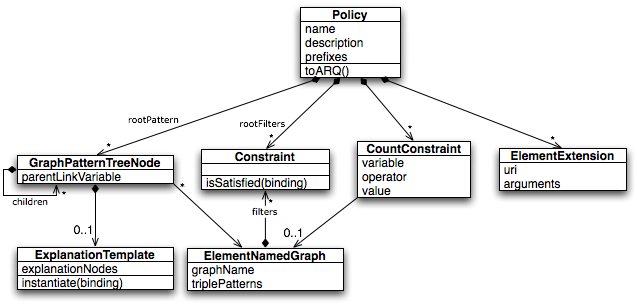
These policies are parsed into a cluster of Java objects centered around the Policy class.
Policies consist of several parts:
The parser's job is to turn a policy, written down in WIQA-PL, into a Policy object. Application programmers access it through the PolicyParser facade, the full implementation is in the de.fuberlin.wiwiss.wiqa.parser package.
The parser is derived from ARQ's SPARQL parser and built using the JavaCC parser generator. Most of the parser code (the javacc subpackage) is automatically generated from a grammar definition file by JavaCC. The grammar file can be found in the distribution as /grammar/wiqa.jj. It was created by adapting ARQ's sparql.jj. Most low-level grammar structures, such as triple patterns or FILTER expressions, have been re-used without change. But the grammar's higher levels have been replaced with grammar rules for WIQA-PL.
While the parser reads a WIQA-PL file, it adds the various parts described in the previous section to a Policy object using its setter methods.
One syntactic construct in WIQA-PL is overloaded with three different features: the extension function syntax.
FILTER ... ext:someQName(?foo, ?bar) ...
When this “QName or URI followed by arguments in brackets” syntax is encountered in a policy, it could be
These features can be distinguished only by the URI. Count constraints use the well-known URI wiqa:count, and all other URIs must be checked against the lists of registered functions and extensions to see which kind it represents.
Distinguishing between these three types is somewhat difficult in the token/rule framework provided by JavaCC. Like most parsers, a JavaCC-generated parser operates in two stages: First, the input string is split into tokens (e.g. keywords, QNames, URIs, literals, punctuation). Second, the stream of tokens is matched against the grammar rules. To cope with the three function types, the WIQA parser has another phase between these two: The token stream is analysed, and URI or QName tokens whose URI is wiqa:count or a registered extension are replaced by special “count” or “extension” tokens. This happens in CustomTokenManager. The grammar rules for count constraints and extensions are defined using these tokens.
This section describes what happens behind the scenes when the output graph is queried.
AcceptedGraph is an implementation of Jena's Graph interface. Like any RDF graph, it is a set of triples. AcceptedGraph is read-only, it doesn't implement methods for adding and removing triples. All the read methods (find, contains, size, query) are implemented in terms of a simple match of a triple pattern against the graph's triples. This match is implemented in the method AcceptedGraph.graphBaseFind(tripleMatch). The basic procedure is as follows:
The rest of this document provides more detail about steps 3, 4 and 5.
Almost all policies have at least one graph pattern. In WIQA-PL, graph patterns appear as a simple list. But for some steps of query processing, it is necessary to order this list into a tree.
Each node in the tree is a tuple (gp, parent, v) where gp is a graph pattern, parent is the parent node, and v is the node's shared variable — a variable that is shared with the parent node's graph pattern.
The graph pattern of the tree's root is rootpattern, the implicit graph pattern
?GRAPH { ?SUBJ ?PRED ?OBJ . }
that is part of every policy. The full tree is constructed recursively by the function buildTree(GP), which takes the set of all graph patterns in the policy and produces a set of nodes interconnected through references to their parents.
buildTree(GP)
input: GP, the set of graph patterns to be arranged as a tree
return buildNodes(rootpattern, undef, undef, GP)
buildNodes(gp, parent, v, GP)
input: gp, a graph pattern
input: parent, a node in the graph parent tree
input: v, a variable shared with the graph pattern of parent
input: GP, the set of graph patterns to be arranged as a tree
n = (gp, parent, v)
nodes = {n}
for each graph pattern gpi in GP
for each variable vj contained in gpi
if vj is contained in gp and
vj is not the shared variable of any node in ancestors(n) U {n}
then
nodes = nodes U buildNodes(gpi, n, vj, GP - {gpi})
return nodes
ancestors(n)
input: n = (parent, gp, v), a node in the graph pattern tree
return {} if parent is undef
return ancestors(parent) U {parent}
The algorithm is implemented in the TreeBuilder class.
This tree is used in two parts of WIQA query evaluation. In count constraints, it is used to separate solutions into groups, and the counting happens within each of the groups. And when explanations are generated, the tree structure of the explanation's parts mirrors the graph pattern tree.
This section describes the algorithm used for evaluating count constraints.
If a policy P is in use, and B is the solution set produced by a request, and the filter condition
FILTER (wiqa:count(?x) > 3)
is encountered in graph pattern gp, then the filter result is determined by the function count(B, ?x, > 3, gp, graph pattern tree of P). gp is undef if the count constraint is located on the root.
A solution is a partial function from variable names to RDF terms.
count(B, vc, condition, gp, t)
input: B, a list of solutions
input: vc, the variable whose values are to be counted
input: condition, a function from integers to {true, false}
input: gp, the graph pattern containing the count constraint
input: t, the policy's graph pattern tree
result = B
if gp = undef then
result = groupAndCount(result, vc, condition, {?SUBJ, ?PRED, ?OBJ})
else
do a depth-first walk of t; for each node n
if gp = the graph pattern of n then
Vp = the set of shared variables of n and all its ancestors
result = groupAndCount(result, vc, condition, {?SUBJ, ?PRED, ?OBJ} U Vp)
The function groupAndCount sorts solutions into buckets, where each bucket contains only solutions with identical values for the some set of group variables Vgroup. This is similar to SQL's GROUP BY feature. Then, in each bucket, the distinct values of another variable vc are counted, and all buckets where the count doesn't match condition are discarded.
groupAndCount(B, vc, condition, Vgroup)
input: B, a list of solutions
input: vc, the variable whose values are to be counted
input: condition, a function from integers to {true, false}
input: Vgroup, a set of variables by which solutions are grouped prior to counting
result = {}
for each groupdef in { groupdef = projection(b, Vgroup) and b in B }
group = { b in B : groupdef is a subset of b }
if condition( |group| ) is true
result = result U group
The projection of a solution on a set of variables V is a new solution that retains only values for variables in V.
projection(b, V)
input: b, a solution
input: V, a set of variables
result = the sub-solution p of b that has
p(v) = b(v) for all v in V, and
p(v) = undef for all other variables
These functions are implemented in the count package, the most important class is QueryIterCount.
This section describes how explanations for an accepted RDF triple are generated from the set of solutions.
An explanation is a set of explanation parts. Each of these is a tuple (text, parts), where text is a list of RDF nodes (usually literals), and parts is a set of explanation parts.
Explanations are generated from explanation templates. An explanation template is a list of RDF nodes and variables. Variables in the template are replaced with actual RDF nodes from a solution when the template is instantiated.
The explanation for an RDF triple rt = (s, p, o) is generated by the function explain(rt, B, root, tree), where B is the solution set, tree is a graph pattern tree as returned by buildTree, and root is its root node.
explain(rt, B, n, tree)
input: rt = (subj, pred, obj), an RDF triple
input: S, a solution set
input: n, a node in the graph pattern tree
input: tree, a graph pattern tree
S' = { s in S where s(?SUBJ) = subj & s(?PRED) = pred & s(?OBJ) = obj }
return makeParts(S', root(tree), tree)
makeParts(S, n, tree)
input: S, a solution set
input: n = (gp, parent, v), a node in the graph pattern tree
input: tree, a graph pattern tree
parts = {}
if gp has an explanation template tpl
Vtpl = set of all variables in tpl
valuesets = {}
for each s in S
valuesets = valuesets U { projection(s, Vtpl) }
for each valueset in valuesets
text = instantiate(tpl, valueset)
solutiongroup = { s in S where valueset subset of s }
parts = {}
for each c in children(n, tree)
childparts = childparts U makeParts(solutiongroup, c, tree)
parts = parts U { (text, childparts) }
else
for each c in children(n, tree)
parts = parts U makeParts(S, c, tree)
return parts
instantiate(tpl, s)
input: tpl = <r1, ..., rn>, a list of RDF nodes or variables
input: s, a solution
return <r1', ..., rn'>, where
ri' = s(ri), if ri is a variable
ri' = ri, otherwise
$Log: index.html,v $ Revision 1.10 2006/06/26 21:58:17 cyganiak Changed iqa: prefix to wiqa: throughout Revision 1.9 2006/06/26 21:42:06 cyganiak Terminology: binding -> solution Revision 1.8 2006/06/26 20:47:49 cyganiak Small improvement to tree building algorithm Revision 1.7 2006/06/21 14:16:11 cyganiak Improved formal algorithms Revision 1.6 2006/06/14 11:59:00 cyganiak Terminology: parent link variable -> shared variable Revision 1.5 2006/06/14 10:19:17 cyganiak Added abstract, small editorial changes Revision 1.4 2006/06/13 15:24:59 cyganiak First complete version. Revision 1.3 2006/06/12 17:56:42 cyganiak - Added UML diagram of Policy and friends - Various revisions to the text Revision 1.2 2006/05/03 11:58:20 cyganiak Added section on graph pattern trees to engine implementation doc Revision 1.1 2006/05/02 13:14:55 cyganiak Half-finished draft of engine architecture/implementation docs.