Data that is published on the Web of Data is represented using a wide range of different vocabularies. Terms from different well-known vocabularies are often mixed and complemented with domain-specific or data source-specific terms. In contrast, applications usually expect data to be represented using a consistent vocabulary. The R2R framework allows you to transform Web data to a user defined target vocabulary. The R2R framework consists of a mapping language for expressing term correspondences and a Java API for discovering and executing mappings. The R2R Famework can be employed within two use cases:
This document specifies the R2R mapping language and describes the R2R Java API.
Data that is published on the Web of Data is represented using a wide range of different vocabularies. Terms from different well-known vocabularies are often mixed and complemented with domain-specific or data source-specific terms. In contrast, applications usually expect data to be represented using a consistent vocabulary. The R2R framework allows you to transform Web data to a target vocabulary. The R2R framework consists of a mapping language for expressing term correspondences and a Java API for transforming data according to the mappings.
The R2R Mapping Language is designed towards the fine-grained representation of modular mappings and for the flexible combination of partial mappings. The basic idea is that you specify mappings between single terms in different vocabularies and that these mappings are then automatically combined in order to transform source data into a given target vocabulary. The syntax of the R2R mapping language is inspired by the SPARQL query language in order to make it easier for developers that already know SPARQL to write mappings. The language provides a wide range of transformation functions and value modifiers which help you to transform property values to the desired target representation.
The R2R Publishing vocabulary makes the R2R mappings accessible to the whole Web and provides the basis to find mappings related to vocabularies or datasets. Mappings that were collected in this way can be feeded to the R2R Discovery which tries to find and combine mappings between a dataset and the given target vocabulary based on a quality assessment heuristic. For the Web use case we also introduce additional meta data to distinguish vocabulary-level and datasource-level mappings to factor in datasource specific assumptions and constraints that are not covered by vocabulary definitions.
The R2R Java API transforms Web data to a given target vocabulary. Input data can be provided as RDF file, Jena Model or can be retrieved from a SPARQL endpoint. Based on a given set of mappings and a given specification of the target vocabulary, the R2R API selects and combines the relevant mappings and transforms the input data into the target vocabulary. In a more Web related use case, the R2R API offers a discovery
This release of the R2R framework is a first step in an effort by the Web-based Systems Group at Freie Universität Berlin to develop languages and tools for the self-descriptive representation of Web data. The idea is that a Web client which discovers data on the Web being represented using vocabulary terms that are unknown to the client should be able to search the Web for vocabulary mappings which allow it to transform the data into a target vocabulary that it understands.
The R2R Framework currently consists of:
The R2R mapping language is designed for publishing mappings as Linked Data on the Web. Thus mappings are represented as RDF and each mapping is assigned its own dereferenceable URI. Similar to the SPARQL query language, the R2R mapping language operates on RDF level and does not rely on any further assumptions about the semantics of Web data.
The R2R mapping language is a declarative language for describing correspondences between terms from different RDF vocabularies.
The R2R namespace is http://www4.wiwiss.fu-berlin.de/bizer/r2r/
The main elements of the R2R mapping language are:
To give a fast overview over the mapping language, the following example sums up how mappings can be expressed:
01: # R2R Namespace
02: @prefix r2r: <http://www4.wiwiss.fu-berlin.de/bizer/r2r/> .
03:
04: # Namespace of the mapping publisher
05: @prefix p: <http://...>
06:
07: # mapping from foaf:Person -> dbpedia:Person
08:
09: p:personClassMapping
10: a r2r:Mapping ;
11: r2r:sourcePattern "?SUBJ rdf:type foaf:Person" ;
12: r2r:prefixDefinitions "foaf: <http://xmlns.com/foaf/0.1/> . dbpedia: <http://dbpedia.org/ontology/>" ;
13: r2r:targetPattern "?SUBJ rdf:type dbpedia:Person" .
14:
15: # Property mapping from foaf:name -> dbpedia:name
16:
17: p:foafNamePropertyMapping2
18: a r2r:Mapping ;
19: r2r:sourcePattern "?SUBJ foaf:name ?o ." ;
20: r2r:targetPattern "?SUBJ <http://dbpedia.org/ontology/name> ?o" ;
21: r2r:prefixDefinitions "foaf: <http://xmlns.com/foaf/0.1/>" .
22:
23: # Property Mapping that only transforms the literal value, but leaves that vocabulary untouched. This is a pure instance level mapping.
24:
25: p:dateValueMapping1
26: a r2r:Mapping ;
27: r2r:sourcePattern "?SUBJ dc:date ?o" ; # date given in a non-xsd:dateTime/xsd:date compatible format: yyyy/mm/dd
28: r2r:targetPattern "?SUBJ dc:date ?'c'^^xsd:dateTime" ;
29: r2r:transformation "?c = concat(infixListConcat('-', split('/', ?o)), 'T00:00:00')" ; # make it compatible
30: r2r:prefixDefinitions "dc: <http://purl.org/dc/elements/1.1/>" .
Basically a mapping constitutes one source pattern, one or more target patterns, optionally prefix definitions for the qualified URIs used inside the source or target patterns, also optionally a reference to a class mapping and also optionally one or more transformation definitions.
Here are some notes for the above examples, each part is discussed more deeply in its own section:
R2R mappings are the main construct of the R2R mappin language. They constitute self-contained units that represent correspondences between terms of two different vocabularies. Each mapping can be executed against a dataset without any further information. Similar to a SPARQL CONSTRUCT clause, a r2r:Mapping has a r2r:sourcePattern and a r2r:targetPattern. Mappings are formulated from a target view. This means that we express how target terms, classes or properties, are mapped from the source. So every triple in the target pattern is independent of the other triples in the target pattern and may be generated by considering merely the source pattern.
The following table lists all the important properties of a R2R mapping:
| r2r:prefixDefinitions | Prefixes used in the source or target patterns
must be defined here. There is no local or base namespace! So :blah
or blah wouldn't work in a pattern. You can have several of these
definitions for one mapping. And prefix definitions are inherited by
referenced mappings or mapping collections. |
| r2r:sourcePattern | Each mapping must have exactly one source pattern. It expresses the pattern of the source vocabulary terms. All of the SPARQL syntax that is valid in a WHERE-clause is allowed here, with the restriciton that properties must be explicit URIs. Also, in order to make it unambiguous which variable in the source pattern corresponds to the mapped resources, the variable ?SUBJ has to be used. |
| r2r:targetPattern | A mapping must have one or more target patterns. One target pattern comprises a set of triples or paths. Paths are just syntactic sugar to express connected/joined triples. There exist several modifier to specify the node type, data type and the language of a target object. See next section for more details. |
| r2r:transformation | Definitions used for transforming property values. See
Transformation section for detailed information. |
| r2r:mappingRef | A reference to another mapping, which can be used to build on the referenced mapping definition. Mainly used to reduce redundancy: The source pattern of the referenced mapping is joined with this source pattern. Prefix definitions don't have to be repeated. |
Since you will most likely use prefixed URIs in your mappings it can be cumbersome to repeat prefix definitions over and over again. Another way to cope with this problem is to define them once for a resource that carries redundant data and make mappings reference this resource. The resource is of type r2r:MappingCollection and is currently only used to carry prefix definitions:
p:mapColl1 a r2r:MappingCollection ;
r2r:prefixDefinitions "dbpedia: <http://dbpedia.org/ontology/> ..." .
This object can be referenced by the r2r:partOfMappingCollection property, so the prefix definitions don't have to be repeated over and over again:
p:mapping1 a r2r:Mapping ;
r2r:partOfMappingCollection p:mapColl1 .
In the following we give some examples of class related mappings, which defines how a class term of the target vocabulary is expressed in the means of the source schema. Mappings are specified as instances of the class r2r:Mapping.
In the following example we have a simple 1 to 1 mapping:
@prefix r2r: <http://www4.wiwiss.fu-berlin.de/bizer/r2r/> .
# Namespace of the mapping publisher
@prefix p: <http://...> .
p:dbpediaToFoafPersonMapping
a r2r:Mapping ;
r2r:prefixDefinitions "foaf: <http://xmlns.com/foaf/0.1/> . dbpedia: <http://dbpedia.org/ontology/>" ;
r2r:targetPattern "?SUBJ rdf:type foaf:Person" ;
r2r:sourcePattern "?SUBJ rdf:type dbpedia:Person" .
This mapping defines that every element of class foaf:Person is also an element of class dbpedia:Person. The instance variable ?SUBJ must be used in every source pattern and is reserved for representing the instances that are the focus of the mapping. In the example above it repesents all dbpedia:Person resources.
As you probably noticed, mappings to a class term always have a target pattern like this: ?SUBJ (a | rdf:type) <classURI>
The next example shows that the source pattern can use any standard SPARQL feature as applicable in a WHERE-clause:
@prefix r2r: <http://www4.wiwiss.fu-berlin.de/bizer/r2r/> .
@prefix p: <http://...> .
p:SpecificPersonClassMapping
a r2r:Mapping ;
r2r:prefixDefinitions "dbpedia: <http://dbpedia.org/ontology/> . otherns : <http://...> " ;
r2r:sourcePattern "?SUBJ rdf:type dbpedia:Person ; dbpedia:spouse ?o ; dbpedia:birthDate ?b . FILTER(?b < "1980-01-01T00:00:00Z"^^xsd:dateTime)" ;
r2r:targetPattern "?SUBJ rdf:type otherns:Pre80MarriedPerson" .
This complex source pattern would match any Person who is married and was born before 1980. These instances will be mapped to instances of the target class otherns:Pre80MarriedPerson.
Next we show some examples where property terms are the target of the mapping.
A property in the target schema can correspond to several properties in the source schema and vice versa. Also for property mappings, the use of value transformations becomes relevant. Transformations express how values from the source and the target pattern relate to each other - also from a target view.
The examples that follow also show different possibilities of how terms correspond to each other. 1-to-1 correspondences relate single terms from each vocabulary. Many-to-1 correspondences relate several terms from the source to one term in the target and 1-to-many the other way round:
@prefix r2r: <http://www4.wiwiss.fu-berlin.de/bizer/r2r/> .
@prefix p: <http://...> .
# Simple 1-to-1 property mapping: foaf:name → dbpedia:name. The source representation of the property value is adopted.
p:oneToOnePropertyMapping
a r2r:Mapping ;
r2r:sourcePattern "?SUBJ foaf:name ?o" ;
r2r:targetPattern "?SUBJ dbpedia:name ?o" ;
r2r:prefixDefinition "foaf: <http://xmlns.com/foaf/0.1/> . dbpedia <http://dbpedia.org/ontology/>" .
# A Many-to-1 property mapping. This type always has to use value transformations to make sense.
p:manyToOnePropertyMapping
a r2r:Mapping ;
r2r:sourcePattern "?SUBJ foaf:firstName ?f . ?SUBJ foaf:lastName ?l" ;
r2r:targetPattern "?SUBJ dbpedia:name ?n" ;
r2r:transformation "?n = concat(?l, ', ', ?f)" ; # Concatenate the first and last name seperated by a comma+space.
r2r:prefixDefinition "foaf: <http://xmlns.com/foaf/0.1/> . dbpedia <http://dbpedia.org/ontology/>" .
# The opposite way of the above mapping. The target pattern reference transformation result variables instead of variables from the source pattern.
p:OneToManyPropertyMapping
a r2r:Mapping ;
r2r:sourcePattern "?SUBJ dbpedia:name ?n" ;
r2r:targetPattern "?SUBJ foaf:firstName ?f" ;
r2r:targetPattern "?SUBJ foaf:lastName ?l" ;
r2r:transformation "?f = getByIndex(split(', ', ?n), 1)" ; # Concatenate the first and last name seperated by a comma+space.
r2r:transformation "?l = getByIndex(split(', ', ?n), 0)" ; # Concatenate the first and last name seperated by a comma+space.
r2r:prefixDefinition "foaf: <http://xmlns.com/foaf/0.1/> . dbpedia <http://dbpedia.org/ontology/>" .
# A "property mapping" referencing a "class mapping".
# This mapping is valid if executed against DBpedia for example. But only for instances that are member of dbpedia:Person/foaf:Person.
# That's why we included the r2r:mappingRef to specify the context in which the mapping ist valid. Without the reference we
# would end up with alot of non-Person instances having a foaf:name property, which would lead to conflicts.
p:labelToNameMapping
a r2r:Mapping ;
r2r:sourcePattern "?SUBJ rdfs:label ?o" ;
r2r:targetPattern "?SUBJ foaf:name ?o" ;
r2r:prefixDefinition "dbpedia <http://dbpedia.org/ontology/>" ; # Note that the rdfs prefix definition is omitted. The R2R API uses the expansion machanism of Jena for common prefixes.
r2r:mappingRef p:dbpediaToFoafPersonMapping . # The class mapping definition can be found in the class mapping section and thus is omitted here.
# A mapping from a schema "Person livesIn Country" to a schema "Person livesIn City locatedIn Country"
# The problem here is that there is no City instance in the source schema, so we have to generate one.
# The target pattern also includes a path, where the object in the middle (?city) isn't repeated.
p:pathPropertyMapping
a r2r:Mapping ;
r2r:prefixDefinitions "..." ;
r2r:sourcePattern "?SUBJ o1:livesIn ?country" ;
r2r:targetPattern "?SUBJ o2:livesIn ?city o2:locatedIn ?country" ;
r2r:transformation "?city = concat('http://target.org/ontology/cities/unknown?', urlencode(?SUBJ))" ; # This generates a dummy URI. The Person will be the only inhabitant of this city.
The target pattern structure is quite simple:
A path has the form: Resource Property, followed by one or more Resource Property parts, and ends with an Object.
Path example:
<...> r2r:targetPattern "?SUBJ dbpedia:spouse ?sp dbpedia:livesIn ?o" .
It follows from above that only the variable ?o can be a literal, all in between must be URI references and thus are automatically converted to URIs.
Constant values and URI references:
Constants can be placed in target patterns like this:
# Use constants in target patterns
<...> r2r:targetPattern
"?SUBJ rdfs:label 'String constant'" ,
"?SUBJ rdfs:label '''Also a string constant, where you can include 's''' " , # " and """ are also possible
"?SUBJ rdfs:label 'language tagged string'@en " ,
"?SUBJ n:height 1.76" , # Decimal constant
"?SUBJ n:height 1.76e0" , # Double constant
"?SUBJ n:height '1.76'^^xsd:double" , # Double constant
"?SUBJ n:age 54" , # Integer constant
"?SUBJ n:hasBeenAccepted true" , # Boolean constant
# Use of URIs in target patterns
<...> r2r:targetPattern
"?SUBJ rdf:type <http://dbpedia.org/ontology/Person>" ;
"?SUBJ dbpedia:movement dbpedia:Renaissance" .
Blank nodes:
Although not recommended for several reasons, it is possible to insert blank nodes in target patterns:
r2r:targetPattern "[] foaf:name ?name" ;
r2r:targetPattern "?SUBJ n:livesInCity _:blabel n:liesInCountry dbpedia:New_Zealand" ;
In the first example there will be created a new unique anonymous node for every variable binding of ?name. In the second example, too, but if the same label is used in any other target pattern of that particular mapping, then the same node will be inserted on both places. In this example the same blank node will be once in subject position and once in object position of the two generated triples. Square bracket blank node syntax like this [ foaf:name ?name ] is not supported, only empty brackets.
To define data types for generated values or modify/add the type and language of literals bound in the source pattern, R2R offers several modifiers for variables appearing in a triple/path. Following modifiers exist:
We present now some examples:
URI modifier:
# If for example the object of a triple in the source dataset is a literal containing a HTTP link, you can convert it to an URI resource by enclosing the variable name in angle brackets:
<...> r2r:targetPattern
"?SUBJ foaf:homepage ?<o>" . # The former string value of the source dataset - associated with ?o - will be a URI reference in the target dataset.
Properties cannot be modified:
# For a property in the Target Pattern, only explicit URIs are allowed. Something like "?SUBJ ?p ?o" does not work! Thus no modifiers could apply.
<...> r2r:targetPattern
"?SUBJ ?p ?o" . # !!! This will throw a parse exception, because only explicit URIs are allowed for properties.
"?SUBJ <http://dbpedia.org/ontology/birthDate> ?o" ,
"?SUBJ prefix:propertyname ?o" . # The latter two target patterns show correct uses for a property in a target pattern
Modifiers for variables in "literal position":
# Most alternatives exist for literals in a target pattern, as said before, literals can only be at the rightmost place in a path/triple.
# If a variable of the source pattern is used in the target pattern without modifier, the source type or language tag is adopted.
<...> r2r:targetPattern
"?SUBJ rdfs:label ?l" # If the source label had a language tag or data type assigned to it, the value in the target dataset will have one, too.
# Modify values taken from the source dataset or generated values from a transformation definition.
# In both cases the lexical values of the input values must have the right format! Trying to transform the lexical value "seven" to an xsd:double will certainly not work ;)
# But transforming values like "seven" into "7" first and then adding a datatype modifier like xsd:integer will work.
<...> r2r:transformation "?c = ..." . # Do a transformation on source values and associate the variable c with the result.
<...> r2r:targetPattern
"?SUBJ rdfs:label ?'c'" , # The generated values are transformed to string literals, this is the standard case! So this is redundant.
"?SUBJ rdfs:lavel ?c" , # Thus, this means the same as the latter pattern, however this only applies for transformed/generated values!
"?SUBJ rdfs:label ?'c'@en " , # Add a language tag to the generated values
"?SUBJ rdfs:label ?'c'^^xsd:decimal" # Convert the variable values to the xsd:decimal data type. Similarly you can use other data types.
Note that data type modifiers influence how numerical values are calculated. Especially if you use the ^^xsd:decimal data type modifier, all numerical functions of a transformation definition that can handle both decimal or double values will switch to decimal calculation.
Transformations are needed if the value format existing in the source dataset differ from the value format or type you want to have in the target dataset. A transformation is defined by an (unused) result variable name followed by an equals sign and a transformation expression:
<...> r2r:transformation "?varname = function('some string', otherFunction(...), andAnotherOne(andSoOn(...)))" ; # nested functions
r2r:transformation "?numericResult = 2 * ?x - calculateSomething(?var2)" ; # A numeric expression
r2r:transformation "?eitherOr = [?x = ?y ? 'either' : 'or']" ; # a conditional expression
Expressions are constructed out of nestable functions. However, as you can see in the examples there are short forms for arithmetic expressions and conditional expressions. These are converted to function calls when being parsed.
Functions can have 0 to n arguments. They can contain constant values like integers, strings etc., functions or arithmetic expressions (+, -, *, / and parentheses) - in other words, arbitrary expressions. The return value of a function is either a single atomic value (always as string representation) or a list of atomic values.
If a list is given as argument where an atomar value is needed the first element of the list is taken and vice versa a single value is treated as a single element list, if a list is needed.
Here are some more examples of transformation definitions:
<...> r2r:transformation
"?c = infixListConcat('-', split('/', ?o))" , # Split a string at slashes and put it together with minus signs in between
"?d = 2 + 643.5 * ?o" , # Multiply 643.5 with the value from the variable ?o of a source pattern and add 2 to it
"?e = [getByIndex(split(':', ?url), 0) = 'http' ? '' ] " .
For some complete mapping examples with transformations see the R2R Mapping section.
Since transformation expressions can result in a single value or a list of values, their use in a target pattern has the following effects:
Example:
<...>
r2r:transformation "?c = split(',', ?o))" ; # Split a string at commas
r2r:targetPattern "?SUBJ foaf:name ?c" . # Depending on how many values were seperated by comma in the value of ?o, that many triples will be generated
Examples for every function are given after the complete listing.
String functions:
| Function | What it does | Returns List? |
|---|---|---|
| join(infix, arg1, arg2, ..., argN) | Concatenates arg1 to argN with the infix string given by the first argument | no |
| concat(arg1, arg2, ..., argN) | Returns a string of the concatenated argument values | no |
| split(regex, stringarg) | Split the second argument at places matching the regex | yes |
| listJoin(infix, list) | Concatenates the values of the list argument with infix inserted inbetween | no |
| regexToList(regex, stringarg) | Returns a list of strings as specified by the regex | yes |
| replaceAll(thisRegex, withThatString, inThisString) | Replaces all matches of the regex with a string | no |
Arithmetic functions:
| Function | What it does | Returns List? |
|---|---|---|
| add(arg1, arg2, ..., argN) or '+' | Add arg1 to argN | no |
| subtract(arg1, arg2, ..., argN) or '-' | Subtract arg2 to argN from arg1 | no |
| multiply(arg1, arg2, ..., argN) or '*' | Multiply arg1 to argN | no |
| divide(arg1, arg2) or '/' | Divide arg1 by arg2 | no |
| integer(arg) | Convert argument to integer value by taking only the integer number part | no |
| mod(arg1, arg2) | returns: arg1 modulo arg2 | no |
List functions:
| Function | What it does | Returns List? |
|---|---|---|
| list(arg1, arg2, ..., argN) | Create a list out of the arguments | yes |
| sublist(listarg, from, to) |
Returns a sub list of the given list argument from index "from" to index "to" (exclusive) | yes |
| subListByIndex(listarg, i1, i2, ..., iN) | Build a list from the given list, but with elements picked as specified by the index arguments | yes |
| listConcat(listArg1, listArg2, ..., listArg3) | Concatenate the list arguments to one list | yes |
| getByIndex(listArg, index) | Get the value at the index of the list argument | no |
| length(arg) | Returns the number of elements in the list. For atomar values this will be 1 | no |
XPath functions:
These are functions mirroring string and numeric XPath functions, as
described under http://www.w3.org/TR/xpath-functions/#string-functions
and http://www.w3.org/TR/xpath-functions/#numeric-value-functions.
The following table does only explain differences, for a function
documentation we link to the respective XPath documentation.
| Function | What it does | Returns List? |
|---|---|---|
| xpath:abs(x) | Returns the absolute value of the argument. | no |
| xpath:ceiling(x) | Returns the smallest number with no fractional part that is greater than or equal to the argument. | no |
| xpath:floor(x) | Returns the largest number with no fractional part that is less than or equal to the argument. | no |
| xpath:round(x) | Rounds to the nearest number with no fractional part. | no |
| xpath:round-half-to-even(x) | Takes a number and a precision and returns a number rounded to the given precision. If the fractional part is exactly half, the result is the number whose least significant digit is even. | no |
| xpath:codepoints-to-string(cp1, ...) | Creates an xs:string from a sequence of Unicode code points. | no |
| xpath:string-to-codepoints(str) | Returns the sequence of Unicode code points that constitute an xs:string. | yes |
| xpath:compare(s1,
s2) xpath:compare(s1, s2, collation) |
Returns -1, 0, or 1, depending on whether the value of the first argument is respectively less than, equal to, or greater than the value of the second argument, according to the rules of the collation that is used. | no |
| xpath:codepoint-equal(s1, s2) | Returns true if the two arguments are equal using the Unicode code point collation. | no |
| xpath:concat(s1, ...) | Concatenates two or more arguments to a string. | no |
| xpath:string-join((s1,
...)) xpath:string-join((s1, ...), separator) |
Returns the string produced by concatenating a sequence of strings using an optional separator. | no |
| xpath:substring(s,
start) xpath:substring(s, start, length) |
Returns the string located at a specified place within an argument string. | no |
| xpath:string-length(s) | Returns the length of the argument. | no |
| xpath:normalize-space(s) | Returns the whitespace-normalized value of the argument. | no |
| xpath:normalize-unicode(s) xpath:normalize-unicode(s, norm) |
Returns the normalized value of the first argument in the
normalization form specified by the second (optional) argument. Note: Implemented normalization forms are NFC (default), NFD, NFKC and NFKD. |
no |
| xpath:upper-case(s) | Returns the upper-cased value of the argument. | no |
| xpath:lower-case(s) | Returns the lower-cased value of the argument. | no |
| xpath:translate(s, map, trans) | Returns the first string argument with occurrences of characters contained in the second argument replaced by the character at the corresponding position in the third argument. | no |
| xpath:encode-for-uri(s) | Returns the string argument with certain characters escaped to enable the resulting string to be used as a path segment in a URI. | no |
| xpath:iri-to-uri(s) | Returns the string argument with certain characters escaped to enable the resulting string to be used as (part of) a URI. | no |
| xpath:escape-html-uri(s) | Returns the string argument with certain characters escaped
in the manner that html user agents handle attribute values that
expect URIs. Note: This is not working correctly to the specification. Try to avoid the function. |
no |
| xpath:contains(s, c) | Indicates whether one string contains another string. Note: Other than in the XPath function, a collation must not be specified. |
no |
| xpath:starts-with(s, c) | Indicates whether the value of one string begins with
another string. Note: Other than in the XPath function, a collation must not be specified. |
no |
| xpath:ends-with(s, c) | Indicates whether the value of one string ends with another
string. Note: Other than in the XPath function, a collation must not be specified. |
no |
| xpath:substring-before(s, c) | Returns the string that precedes in that string another
string. Note: Other than in the XPath function, a collation must not be specified. |
no |
| xpath:substring-after(s, c) | Returns the string that follow in that string another
string. Note: Other than in the XPath function, a collation must not be specified. |
no |
| xpath:matches(s, pattern) | Returns an boolean value that indicates whether the value of
the first argument is matched by the regular expression that is the
value of the second argument. Note: There may be differences to the XPath regular expression syntax. If in doubt, consult the Java regex syntax. |
no |
| xpath:replace(s, pattern, replacement) | Returns the value of the first argument with every substring
matched by the regular expression that is the value of the second
argument replaced by the replacement string that is the value of the
third argument. Note: There may be differences to the XPath regular expression syntax. If in doubt, consult the Java regex syntax. |
no |
| xpath:tokenize(s, pattern) | Returns a sequence of one or more strings whose values are
substrings of the value of the first argument separated by substrings
that match the regular expression that is the value of the second
argument. Note: There may be differences to the XPath regular expression syntax. If in doubt, consult the Java regex syntax. |
yes |
Examples of function usage:
All examples represent string values of the r2r:transformation property.
String functions:
# Join several strings by '-': ('2010', '07', '01') → '2010-07-01'
?joinedString = join('-', ?year, ?month, ?day)
# Concatenate several strings:
?concatenatedString = concat('Hello ', 'World')
# Split a date: '2010-07-01' → ['2010', '07', '01'] and join the list again
?sameAsDate = listJoin('-', split('-', ?date))
# Do the same as with the split function in the previous example, but with regexToList
?interestingStrings = regexToList('(.*)-(.*)-(.*)', ?date)
# Replace all occurrences of '-' by '/' in the date string
?formatedDate = replaceAll('-', '/', ?date)
Arithmetic functions:
# Basic arithmetic operators
?six = subtract(multiply(add(1, 2, 3), divide(3, 2)), 1, 2)
or shorter
?six = (1+2+3)*(3/2) - 1 - 2
# Truncate the non-integral part. The following gives 3
?intPart = integer(10/3)
# Get the modulo. The following returns 1
?rest = mod(10,3)
# modulo also works with floating point numbers, the following returns circa 0.1 (not exact, because of floating point arithmetic!)
# If you modified the transformation variable in the target pattern like this: ?'rest'^^xsd:decimal you get exactly 0.1
?rest = mod(10,3.3)
List functions:
Note that the index of the first element of a list is 0.
# Create a list out of single arguments
list(1, 2, 3) → [1, 2, 3]
# Get the second and third element of a list: [1, 2, 3, 4] → [2, 3]
subList(list(1, 2, 3, 4), 1, 3) → [2, 3]
# Construct a list from another list given the indexes: [1, 2, 3, 4, 5] → [4, 2]
subListByIndex(list(1, 2, 3, 4, 5), 3, 1) → [4, 2]
# Concatenate lists to one list ([1, 2, 3], [4, 5]) → [1, 2, 3, 4, 5]
listConcat(list(1, 2, 3), list(4, 5)) → [1, 2, 3, 4, 5]
# Get a single element of a list [1, 2, 3] → 3
getByIndex(list(1, 2, 3), 2) → 3
# Length of a list [1, 2] → 2
length(list(1, 2)) → 2
length(1) → 1
There is also an If-Then-Else like construct. The syntax is: [ expression CompOp expression ? expression : expression ] where expression can be anything that's allowed on the right hand side of the equal sign of a transformation definition and CondOp is one of the following comparison operators: <, <=, =, >=, >, !=
Example:
... r2r:transformation "?varname = concat([?sex = 'female' ? 'Ms. ' : 'Mr. '], ?lastname)"
It is possible to associate mappings with external Function resources (located in the classpath, file system, remote URL etc.). Functions have to be provided as Java class, so most major languages that compile to Java byte code should be able to implement the necessary Interfaces Function and FunctionFactory. To use an external function in a mapping you can refer to it like this:
:mapping a r2r:Mapping ;
r2r:importFunction "functionName = http://domain/functions/function1" ;
This will import the function with the URI right of the equal sign under the supplied function name. In the transformation definitions for this mapping, the function can then be called with the function name.
A function resource has the following properties:
ef:function1 a r2r:TransformationFunction ;
r2r:codeLocation <http://domain/functioncode/function1.jar> ;
r2r:qualifiedClassName "de.fuberlin.wiwiss.r2r.external.FunctionFactory1" .
Before external code is loaded, the function loader unit always tries to load the code from the class path. So even if you specified a code location in the Transformation Function definition, classes that it can find on the class path are loaded instead. By default this is also the only way to add external functions to the R2R engine, because loading of external code is disabled. If you want to enable this feature - hopefully being aware of potential security risks - you can change the following attribute in the r2r.properties file:
r2r.FunctionManager.loadFromURLs=true
This allows to load new functions during operation and avoids restarting the R2R engine.
In order to enable Linked Data applications to discover mappings on the Web, R2R mappings can be interlinked with RDFS or OWL term definitions as well as with voiD dataset descriptions. Furthermore the vocabulary allows describing the applicability of mappings. This enables vocabulary or dataset publisher as well as third parties to hint applications searching for appropriate mappings to the right direction.
In the last section you already learned about the functional mapping properties that make a mapping work. Here on the other hand we explain the mapping meta data - data that describes mappings and their context they are applicable in.
Besides the typically used properties to describe resources like:
rdfs:label, rdfs:comment, dc:date, dc:creator
we also introduce new properties that in addition to their informative benefit are actually used for finding mappings on the Web or to chain mappings in our discovery process:
With these links on hand a linked data crawler like ldspider can now find mappings by following links from vocabularies to mappings and the other way round. The same applies for voiD dataset descriptions. This will enable us to find mappings that are linked by vocabulary or dataset publisher. To find mappings from third parties search engines like Sindice can be used. Queries like "list all mappings that map to foaf:name" can easily be stated with these search engines to find mapping resources.
The r2r:sourceDataset and r2r:targetDataset properties mentioned before may be a bit confusing, that's why we explain their importance for the Web publishing use case in greater depth.
As different data sources use different value formats to represent values of the same RDF property, the R2R Mapping Language distinguishes between vocabulary-level mappings and dataset-level mappings. Vocabulary-level mappings are usually more generic and might be applied to transform data from and to all data sources that use a specific vocabulary term. Dataset-level mappings specify how data should be translated between two specific data sources. They usually define more detailed transformations to overcome property value heterogeneity, for instance by normalizing different units of measurement or by adding language tags or data types to property values. Mixed cases are also possible, where instead of two data sources, the source or the target is actually on vocabulary level.
To make the point clear, we give examples for every of the four possible combination: No dataset specified, both source and target dataset specified, only target dataset or only source dataset specified. Lets suppose there are two vocabularies vocA and vocB and both vocabularies define name, lastName and firstName properties. The name property in both vocabularies is not constrained any further other than that it must be a string describing the name of a person. Now, there is also a data source dsA using the property vocA:name, but consistently uses a specific format for this property - for example "last name, first name" - and a dataset dsB with vocB:name, but with a different format - "first name last name". Then the four possible combinations are:
So here is where the properties r2r:sourceDataset and r2r:targetDataset come into play.
If a mapping applies property value transformations or structural transformations that only make sense on specific input data, the mapping publisher can restrict the scope of the mapping to be used only with input data that conforms to the publishing pattern of a specific data source by adding a r2r:sourceDataset triple to the mapping pointing at the voiD dataset description of the data source. This means that the mapping makes assumptions about the input data that go beyond the specification of the source vocabulary term.
Similarly, if a mapping applies value transformations or structural transformations to produce data according to the publishing pattern of a specific data source, the mapping publisher can annotate the mapping to produce specific output by interlinking it with the voiD description of the target dataset using the r2r:targetDataset link type.
The main benefits of distinguishing dataset level and vocabulary level mappings are:
In the following we present two examples on how to publish:
Example 1: Here we define two mappings that are directly referenced by the (DBpedia) vocabulary publisher. The mappings are vocabulary mappings, which means that they are not written with concrete datasets in mind.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix r2r: <http://www4.wiwiss.fu-berlin.de/bizer/r2r/> .
@prefix dbpedia-owl: <http://dbpedia.org/ontology/> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
# Vocabulary definitions, note the reference to the mappings
dbpedia-owl:Person a owl:Class ;
rdfs:label "person" ;
rdfs:subClassOf owl:Thing ;
r2r:hasMapping dbpedia:mappingX .
dbpedia-owl:director a owl:ObjectProperty ;
rdfs:label "director" ;
rdfs:range dbpedia-owl:Person ;
r2r:hasMapping dbpedia:mappingY .
# Mapping specific data
dbpedia:mappingX
a r2r:ClassMapping ;
r2r:sourcePattern "?SUBJ a foaf:Person" ;
r2r:targetPattern "?SUBJ a dbpedia:Person" ;
r2r:prefixDefinitions "foaf: <http://xmlns.com/foaf/0.1/> . dbpedia: <http://dbpedia.org/ontology/>" .
dbpedia:mappingY
a r2r:PropertyMapping ;
r2r:sourcePattern "?SUBJ dbpedia:director ?o" ;
r2r:targetPattern "?SUBJ movie:director ?o" ;
r2r:prefixDefinitions "dbpedia: <http://dbpedia.org/ontology/> . movie: <http://data.linkedmdb.org/resource/movie/>" .
# Meta Data for mappings
dbpedia:mappingX
rdfs:label "FOAF to DBpedia Person class mapping" ;
dc:date "2010-04-23" ;
dc:creator <http://somedomain/person/jonDoe> .
dbpedia:mappingY
rdfs:label "DBpedia to Linkedmdb director property mapping" ;
dc:date "2010-04-24" ;
dc:creator <http://somedomain/person/jonDoe> .
Example 2: Here a dataset maintainer wants to define mappings that are dataset specific between his and the DBpedia dataset. To make this explicit, the r2r:sourceDataset and r2r:targetDataset properties point to the voiD description of the participating datasets. If anyone wants to map data between exactly these two datasets, this mapping is preferable to a vocabulary mapping.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix r2r: <http://www4.wiwiss.fu-berlin.de/bizer/r2r/> .
@prefix dbpedia-owl: <http://dbpedia.org/ontology/> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix po: <http://somedomain/ontology/> .
@prefix pd: <http://somedomain/data/> .
@prefix void: <http://rdfs.org/ns/void#> .
# Vocabulary definitions, note the reference to the mappings
po:weight a owl:DatatypeProperty ;
rdfs:label "weight" ;
rdfs:comment "weight in kilogram" ;
rdfs:domain owl:Thing ;
rdfs:range xsd:double ;
r2r:hasMapping pd:weightDBpediaMapping .
# Mapping specific data: From DBpedia to an invented vocabulary/dataset
# Converting a weight value given in gram to kilo
pd:weightDBpediaMapping
r2r:prefixDefinitions "po: <http://somedomain/ontology/> . dbpedia: <http://dbpedia.org/ontology/>" ;
r2r:sourcePattern "?SUBJ dbpedia:weight ?wGrams" ;
r2r:targetPattern "?SUBJ po:weight ?wKilos" ;
r2r:transformation "?wKilos = ?wGrams / 1000.0" .
# Meta Data for mapping. r2r:sourceDataset and r2r:targetDataset state that this mapping was written for specific datasets
pd:weightDBpediaMapping
rdfs:label "DBpedia to somedomain weight property mapping" ;
rdfs:comment "Weight values are transformed from gram to kilo double values" ;
dc:date "2010-05-01" ;
dc:creator <http://somedomain/persons/johnSmith> ;
r2r:sourceDataset dbpedia:voiDdbpedia ; # resource describing the DBpedia dataset
r2r:targetDataset pd:voiDpd . # resource describing the target dataset, see below
# voiD description of target dataset
pd:voiDpd
a void:Dataset ;
dcterms:title "Some dataset" ;
void:uriRegexPattern "http://somedomain/data/.*" . # regex pattern that classifies URIs of the dataset
This chapter describes how R2R mappings are used by Linked Data applications to translate Web data to an application-specific target schema. Here we describe the architecture of the application. For usage details consult section 5.6 of this document.
The goal of the application is to extract data from various Web datasets according to a given definition of the target data. This definition is given by a target vocabulary (see 5.6.1 for details) that your own application can understand and work with. By automatically choosing and applying R2R mappings to transform the original data, the target ouput is eventually achieved and can then be used by your application.
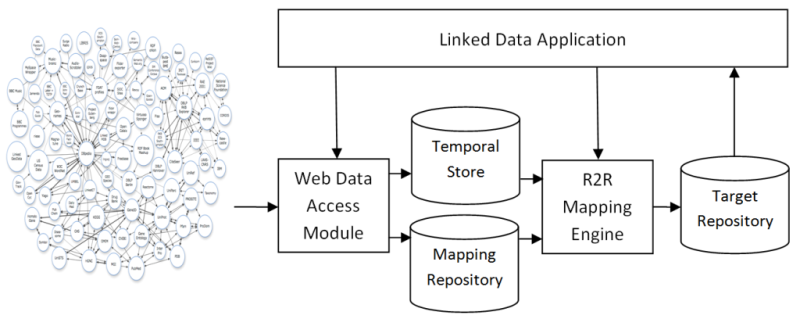
An overview of the architecture:
The architecture consists of a Web Data Access Module which retrieves RDF data from the Web by following RDF links. The access module stores Web data in a Temporal Store. The data is represented as a set of Named Graphs where all data from one data source is contained in its own Named Graph. These graphs are called dataset graphs. If available the URI of the corresponding voiD description is attached to each dataset graph. R2R mappings that are discovered on the Web are stored in a Mapping Repository. In addition to discovering mappings by following RDF links, the Web Data Access Module also queries the Semantic Web Search engines Sindice and FalconS for further R2R mappings. This ensures that third party mappings are also discovered. The application provides the R2R Mapping Engine with a description of the target vocabulary. The description consists of a simple set of URIs identifying the terms (properties as well as classes) of the target vocabulary. The mapping engine translates the data from the temporal store into the target vocabulary and stores the resulting triples in the target repository. Afterwards, it deletes the data in the temporal store. The application can now issue queries using the target vocabulary against the target repository.
If the application wants property values to have a specific format, for instance last name, first name or a distance being given in kilometers, it can instruct the mapping engine to produce only triples in this format by annotating the corresponding target vocabulary term with the URI of the voiD description of a data source that provides exactly this value format. The mapping engine will then only consider mappings having this voiD description as r2r:targetDataset annotation as the last element of the mapping chain and will thus only produce property values having this format.
The goal of the discovery process is to find mappings between specific source datasets, we want to extract data from, and the target vocabulary definition for the output data. The results of this process are not only direct mappings that can be executed against the source dataset to produce the output data, but also chains of mappings, if no direct mapping can be found. These mapping chains resemble trees. The leaves are being directly fed by the source dataset and the data flows through the tree being transformed at every level until it arrives at the root, which produces the final output data.
As example we repeat the example given before in 4.1.2:
foaf:name → (vocA:firstName, vocA:lastName) → vocB:name
Here foaf:name is found in the dataset, but no direct mapping to vocB:name could be found. So instead foaf:name is split and transformed into vocA:firstName and vocA:lastName with an existing mapping for this specific dataset. These results are then combined again with another mapping that produces the vocB:name triples. This mapping chain constitutes a tree, with vocB:name as the root node having two children - vocA:firstName and vocA:lastName - each having exactly one child, foaf:name.
The algorithm that finds these mapping chains, builds a search graph of the mappings and assesses the quality of each mapping chain in the graph by applying quality heuristics, ending with the best rated mapping chain according to these heuristics.
This leads to the conclusion that you profit most by specifying mappings from your own dataset/vocabulary to datasets or vocabularies that are already heavily linked on the mapping level, because this opens alot of potential paths to other datasets and vocabularies.
This section describes how the R2R Java API is used to transform RDF datasets. The interface of the R2R API consists of:
Full examples with Java code, mappings, input data and instructions are given in the example section of the R2R overview document.
The Source interface decouples from different source dataset representations. Currently R2R offers to wrap datasets existing as files, (dereferencable) URIs, SPARQL endpoints or Jena Models. These Source objects can then be used as source datasets in the mapping process and as we will see later also as repositories.
Here are some usage examples:
//Create a source object of a file on hard disk. The "file:" qualifier is optional.
Source fileSource = new FileOrURISource("file:dataset.nt");
//Create a source object of a SPARQL endpoint. There are also other constructors
Source sparqlEndpointSource = new SparqlEndpointSource("http://dbpedia.org/sparql");
//Create a source object of an existing Jena model
Model model = ... //insert code to get the Jena model
Source jenaModelSource = new JenaModelSource(model);
Analogous to the Source Interface there is an Output
Interface to handle the target data of the mapping process. The Output
interface offers similar possibilities:
// An N-Triples file output. The output will be continuously written to disk, instead of storing the target dataset in memory first.
Output ntriplesFile = new NTriplesOutput("outputdataset.nt");
// An RDF/XML file output. The output will be stored in-memory until the object is closed and only then written to disk.
Output rdfxmlFile = new RDFXMLOutput("outputrdf.xml");
// To support output to RDF stores and of course to make mapped datasets directly reusable inside Jena, there is also a Jena Model output
Model model = ...//Get Jena model
Output jenaModelOutput = new JenaModelOutput(model);
// SPARQL Update Output TODO
Repositories hold mappings and/or mapping meta-data. The latter is used to find appropriate mappings and describe things like: what classes or properties mappings map to and what classes and properties mappings depend on in the source dataset. Since a Repository object internally uses a Source object, the same possibilities of the Source-section also applies for Repositories.
The following examples show some possibilities of how to create repositories:
// Create a Repository object from a Source object
Source source = ...//create source object
Repository repository = new Repository(source);
// The R2R API also offers following factory methods:
Model model = ...//Create Jena Model
Repository r1 = Repository.createJenaModelRepository(model);
Repository r2 = Repository.createFileOrUriRepository("mapping-file.nt");
Repository r3 = Repository.createSparqlEndpointRepository("http://somehost.org/repository/sparql");
The above methods only apply to mapping data that consists entirely of R2R mappings. The R2R API also offers functions to import simple mappings expressed in RDFS or OWL, more precisely subClassOf, subPropertyOf, equivalenceClass and equivalenceProperty mappings. The following static functions are defined in the Repository Class:
// Import R2R and other mappings from a file
Model mappings = Repository.importMappingDataFromFile(filename, uriGenerator);
// Import R2R and other mappings from a Source object
mappings = Repository.importMappingDataFromSource(source, uriGenerator);
// Import R2R and other mappings from a Source object into the specified Jena Model object
Repository.importMappingDataFromSourceIntoModel(source, outputModel, uriGenerator);
// Import only OWL mapping (equivalenceClass, equivalenceProperty) into Jena Model from Source object
Repository.importOWLMappingData(source, outputModel, uriGenerator);
// Import only RDFS mapping (subClassOf, subPropertyOf) into Jena Model from Source object
Repository.importRDFSMappingData(source, outputModel, uriGenerator);
The uriGenerator object is an object of type StringGenerator which defines only one method: nextString(): String. As the name implies this object is used to generate URIs for the imported RDFS and OWL mappings. An example declaration of EnumeratingURIGenerator which implements the StringGenerator interface looks like this:
// Create an URI generator that generates URIs: <http://nodomain/ImportedMapping1>, <http://nodomain/ImportedMapping2> etc.
// The first argument is the base and the second parameter is the integer that is appended to the base and increases every call.
StringGenerator uriGenerator = new EnumeratingURIGenerator("http://nodomain/ImportedMapping", BigInteger.ONE);
The Mapper Class offers some static methods that execute the mappings on a Source object and write the output dataset to the Output object. In order for the Mapper to know which mappings it should actually execute and in what way, it expects a Repository objects and a target vocabulary description (see next section).
The following example shows what the complete mapping process can look like:
// Read a mapping file from disk
Repository repository = Repository.createFileOrUriRepository("mapping-file.nt");
// Create an object for the Source dataset
Source source = new SparqlEndpointSource("http://data.linkedmdb.org/sparql");
// Create an output object. Write output to file as N-Triples
Output output = new NTriplesOutput("output.nt");
// Transform source dataset into target dataset as specified by the plain text vocabulary description
Mapper.transform(source, output, repository, ""@prefix dbpedia: <http://dbpedia.org/ontology/> ." +
"@prefix foaf: <http://xmlns.com/foaf/0.1/> ." +
"foaf:Person(foaf:Person, dbpedia:name, foaf:homepage)");
The target vocabulary is specified as a list of target properties. Instances in the output dataset will be described by all or a subset of these properties. In addition, it is possible to apply class restrictions. If a class restriction is applies, all instances in the output dataset will be instances of the specified class or classes. In the following we will discuss several example target vocabulary specifications:
Output all triples having a dbpedia:name or a foaf:homepage property. Do not restrict the output by class.
"(dbpedia:name, foaf:homepage)"
Output all instances having a dbpedia:name and/or a foaf:homepage. Restrict the output to contain only instances of the class foaf:Person. The plus sign behind foaf:Person means that the "rdf:type foaf:Person" statement will also be generated. If it is missing only statements including the properties inside parentheses are generated.
"foaf:Person+(dbpedia:name, foaf:homepage)"
Output all instances having a dbpedia:name and/or a foaf:homepage. Restrict the output to contain only instances of the classes foaf:Person or dbpedia:Person. No rdf:type statements are generated because of the missing plus signs behind the class URIs.
"foaf:Person, dbpedia:Person(dbpedia:name, foaf:homepage)"
Output all foaf:Person instances together with the rdf:type statement, dbpedia:name and a foaf:homepage properties. Also output all dbpedia:Book instances with dbpedia:name and a dc:author properties.
"foaf:Person+(dbpedia:name, foaf:homepage)
dbpedia:Book+(dbpedia:name, dc:author)"
The target vocabulary specification can be provided to a D2R Mapper instance using three different ways:
Plain text descriptions were used in the above examples.
/* Vocabulary description in this example:
"@prefix dbpedia: <http://dbpedia.org/ontology/> ." +
"@prefix foaf: <http://xmlns.com/foaf/0.1/> ." +
"foaf:Person+(dbpedia:birthDate, foaf:name)" +
"(rdfs:label)"
*/
// Define source, output and repository
...
// Execute mappings from repository on source and output the result to output. The mappings adhere to the text vocabulary description.
Mapper.transform(source, output, repository, "" +
// Prefix definitions (rdfs prefix is predefined)
"@prefix dbpedia: <http://dbpedia.org/ontology/> ." +
"@prefix foaf: <http://xmlns.com/foaf/0.1/> ." +
// The following mappings are constrained to resources that can be mapped to foaf:Person resources.
// For these resources, mappings that map to the properties specified in the brackets, will also be executed.
"foaf:Person(dbpedia:birthDate, foaf:name)" +
// The property mappings that map to rdfs:label are not further constrained and will be executed against all resources.
"(rdfs:label)";
Although descriptions could be published as string with the plain text descriptions from above, there is also a little bit finer-grained RDF structured format. Instead of providing a string description to the Mapper function, a URI of the description is supplied. An example how descriptions are represented in RDF is given below:
# R2R Namespace
@prefix r2r: <http://www4.wiwiss.fu-berlin.de/bizer/r2r/> .
# Other namespaces
@prefix dbpedia: <http://dbpedia.org/ontology/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
# These descriptions represent exactly the same as in the above plain text example, but as you can see are separated into two description resources.
<http://.../targetVocabDescription1>
r2r:classRestriction foaf:Person ;
# If you also want to generate rdf:type statements of this class use classRestrictionAndTarget instead
# r2r:classRestrictionAndTarget foaf:Person ;
r2r:targetProperty foaf:name ;
r2r:targetProperty dbpedia:birthDate .
# Specification without class restriction
<http://.../targetVocabDescription2>
r2r:targetProperty rdfs:label .
// Execute it the following way. The RDF descriptions of the vocabulary must be present in "vocabRepository".
Repository vocabRepository = new ...// Create a Repository which includes the vocabulary descriptions
Mapper.transform(source, output, repository, vocabRepository, "http://.../targetVocabDescription1");
To represent the same description in pure Java code, you would do the following:
...
// Class Restriction
List<String> classRestrictions = new ArrayList<String>();
classRestrictions.add("http://xmlns.com/foaf/0.1/Person");
// The entities you want to have in your target dataset
List<String> targetProperties = new ArrayList<String>();
targetProperties.add("http://xmlns.com/foaf/0.1/name");
targetProperties.add("http://dbpedia.org/ontology/birthDate");
// Execute it. The last argument is the equivalent to the plus sign behind the class URIs in the plain text description.
Mapper.transform(source, output, repository, classRestrictions, targetProperties, true);
// Or without class restriction
Mapper.transform(source, output, repository, targetProperties);
The mapping discovery component has the function of finding appropriate mappings for a given dataset. The mappings that are collected in a central repository are not constrained in any way. This means in particular that they use all features of the language and map between arbitrary vocabularies and datasets. Besides finding single direct mappings, it also tries to chain mappings together in order to transform data by piping it through. For example: A mapping chain from foaf:name to v1:lastName and then to v2:lastName if no direct mapping between foaf:name and v2:lastName exists. These mapping chains can also split, so they actually form a tree with the root mapping generating the final output data.
The vocabulary description for the discovery looks slightly different:
@prefix dbpedia: <http://dbpedia.org/ontology/>
@prefix foaf: <http://xmlns.com/foaf/0.1/>
(dbpedia:birthDate, foaf:name^dbpedia:dbpediaVOID)
(dbpedia:birthDate, foaf:name)^dbpedia:dbpediaVOID
First of all there is no class restriction, so this is more like a bulk mapping operation on the level of single vocabulary terms. Secondly there is an optional dataset indication, in this case, the caret (^) sign with dbpedia:dbpediaVOID following, which specifies the dataset. This means that the output data should not only comply to the vocabulary term specification, in this case foaf:name, but also to the same value format as in the DBpedia dataset. For the chaining this especially means that the root mapping will always be a dataset specific mapping, in this case one, that defines dbpedia:dbpediaVOID for the r2r:targetDataset property.
The second expression is a short form to specialize all terms inside the brackets and is used instead of appending the dataset indication to every single vocabulary term. Additional indications for individual terms may overwrite this indication.
If you don't care if a name is represented as "John Doe" or as "Doe, John" then you can omit this indication and in this way benefit from a larger set of potential mappings.
Here is an example on how to apply discovery in your application:
import de.fuberlin.wiwiss.r2r.*;
import de.fuberlin.wiwiss.r2r.discovery.*;
...
Source in = ...
Output out = ...
// Assuming that both mapping data and mapping meta data reside in the same repository
Repository repository = ...
/* DatasetChecker is an interface to find out about the vocabulary terms of a Source object.
This particular implementation queries the Source dataset directly.
*/
DatasetChecker datasetCheck = new SourceDatasetChecker(in);
/* The MappingDiscovery class works with the mapping meta data to find appropriate mapping chains
*/
MappingDiscovery discovery = new MappingDiscovery(datasetCheck, repository);
/* Calculate a mapping chain for the given arguments, where:
targetVocabularyElementURI is the URI string of the vocabulary term you are interested in,
sourceDatasetURI is the (voiD) URI of the source dataset you want to transform,
targetDatasetURI for specifying the value format as described above and
mappingMaxChainDepth as a parameter on how deep the search should go and how long the mapping chain can be.
*/
MappingChain mChain = discovery.getMappingChain(targetVocabularyElementURI, sourceDatasetURI, targetDatasetURI, mappingMaxChainDepth);
// Then execute it!
if(mChain.isExecutable())
mChain.execute(in, out, repository);
And here we exemplify how you can supply a target vocabulary discription as shown above to the Mapping Discovery:
// imports and Source, Output objects as in the previous example
...
int maxDepth = ...
String targetVocabularyDescription = ...
String sourceDatasetVoidURI = ...
Collection<MappingChain> mcs = discovery.getMappingChains(targetVocabularyDescription, sourceDatasetVoidURI, maxDepth);
// Now execute the mapping chains on the dataset
for(MappingChain mc: mcs) {
if(mc.isExecutable()) {
System.out.println("Executing mapping chain for target term " + mc.getTargetVocabularyTerm() + " with score " + mc.getScore());
mc.execute(in, out, repository);
}
}